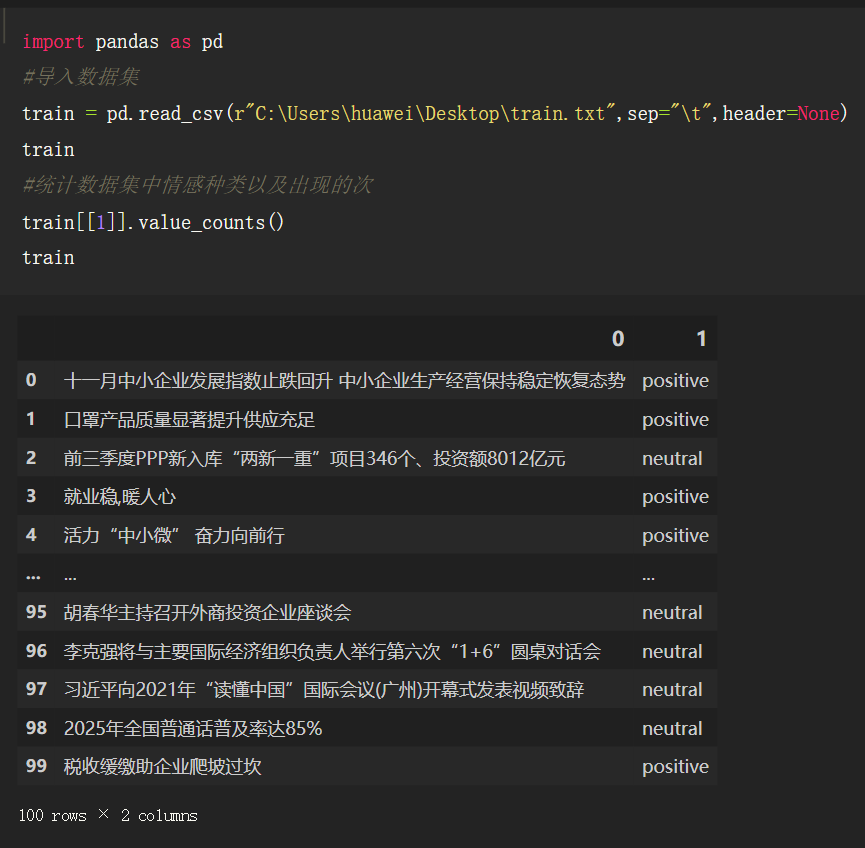
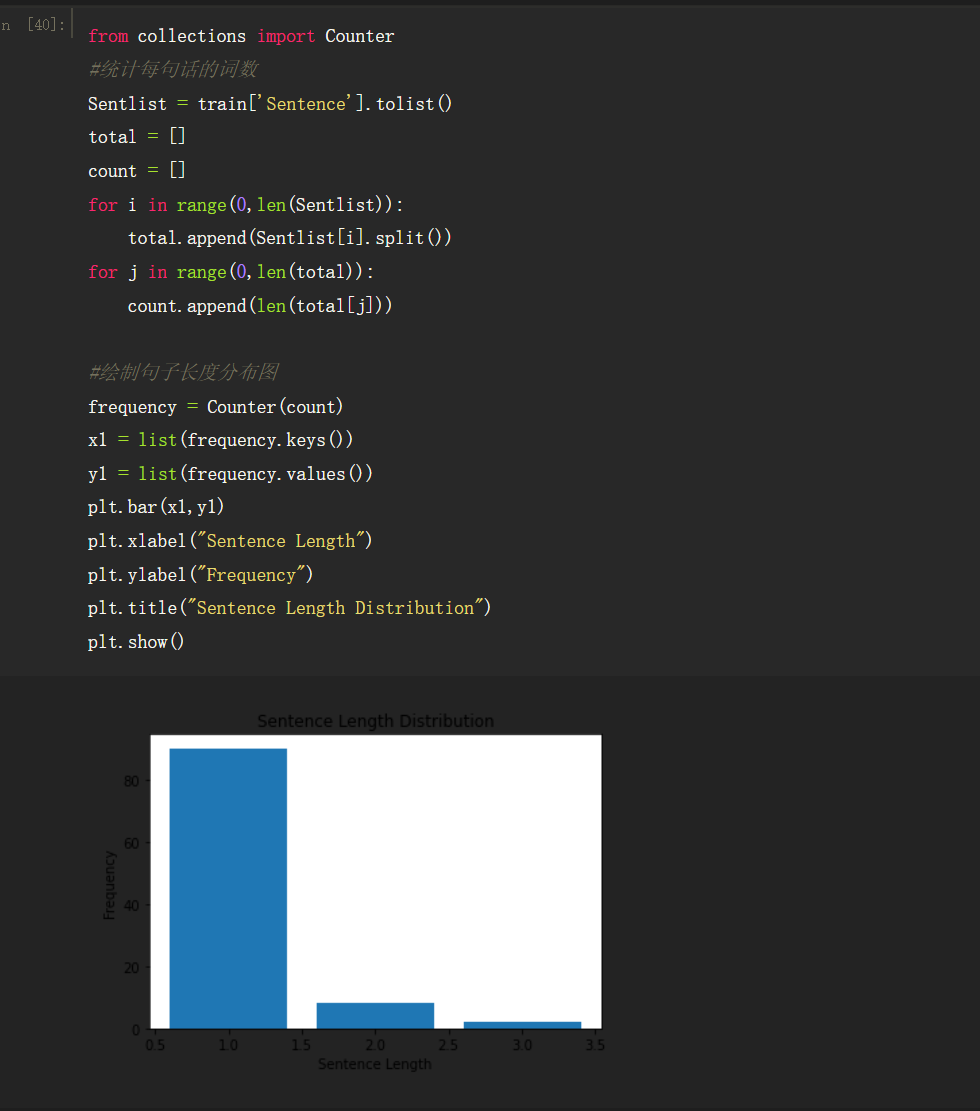
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
| n1 = 0
n2 = 0
n3 = 0
n4 = 0
newLines = ""
with open("train.txt", "r", encoding="UTF-8",errors='ignore') as f:
lines = f.readlines()
f.close()
for line in lines:
label,sentence =line.strip().split('\t')
if int(label) == 0:
if n1 < 10000:
n1 += 1
newLines += label + "\t" + sentence + "\n"
if int(label) == 1:
if n2 < 10000:
n2 += 1
newLines += label + "\t" + sentence + "\n"
if int(label) == 2:
if n3 < 10000:
n3 += 1
newLines += label + "\t" + sentence + "\n"
if int(label) == 3:
if n4 < 10000:
n4 += 1
newLines += label + "\t" + sentence + "\n"
with open("small_train.txt", "w") as f2:
f2.write(newLines)
f2.close()
def regex_filter(s_line):
special_regex = re.compile(r"[a-zA-Z0-9\s]+")
en_regex = re.compile(r"[.…{|}#$%&\'()*+,!-_./:~^;<=>?@★●,。]+")
zn_regex = re.compile(r"[《》!、,“”;:()【】]+")
s_line = special_regex.sub(r"", s_line)
s_line = en_regex.sub(r"", s_line)
s_line = zn_regex.sub(r"", s_line)
return s_line
def stopwords_list(file_path):
stopwords = [line.strip() for line in open(file_path, 'r', encoding='utf-8').readlines()]
return stopwords
word_freqs =Counter()
stopword = stopwords_list("停用词.txt")
max_len = 0
with open('train.txt', 'r+', encoding="UTF-8",errors='ignore') as f:
lines = f.readlines()
for line in lines:
label,sentence =line.strip().split('\t')
sentence = regex_filter(sentence)
words = jieba.cut(sentence)
x = 0
for word in words:
if word not in stopword:
print(word)
word_freqs[word] += 1
x += 1
max_len = max(max_len, x)
print(max_len)
print('nb_words ', len(word_freqs))
MAX_FEATURES = 80000
vocab_size = min(MAX_FEATURES, len(word_freqs)) + 2
word2index = {x[0]: i+2 for i, x in enumerate(word_freqs.most_common(MAX_FEATURES))}
word2index["PAD"] = 0
word2index["UNK"] = 1
with open('word_dict.pickle', 'wb') as handle:
pickle.dump(word2index, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open('word_dict.pickle', 'rb') as handle:
word2index = pickle.load(handle)
MAX_FEATURES = 80002
MAX_SENTENCE_LENGTH = 110
num_recs = 0
with open('train.txt', 'r+', encoding="UTF-8",errors='ignore') as f:
lines = f.readlines()
for line in lines:
num_recs += 1
X = np.empty(num_recs,dtype=list)
y = np.zeros(num_recs)
i=0
with open('train.txt', 'r+', encoding="UTF-8",errors='ignore') as f:
for line in f:
label,sentence =line.strip().split('\t')
words = jieba.cut(sentence)
seqs = []
for word in words:
if word in word2index:
seqs.append(word2index[word])
else:
seqs.append(word2index["UNK"])
X[i] = seqs
y[i] = int(label)
i += 1
X = sequence.pad_sequences(X, maxlen=MAX_SENTENCE_LENGTH)
y1 = pd.get_dummies(y).values
print(X.shape)
print(y1.shape)
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y1, test_size=0.1, random_state=42)
EMBEDDING_SIZE = 256
HIDDEN_LAYER_SIZE = 128
BATCH_SIZE = 64
NUM_EPOCHS = 5
model = Sequential()
model.add(Embedding(MAX_FEATURES, EMBEDDING_SIZE,input_length=MAX_SENTENCE_LENGTH))
model.add(SpatialDropout1D(0.2))
model.add(LSTM(HIDDEN_LAYER_SIZE, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(4, activation="softmax"))
model.add(Activation('softmax'))
model.compile(loss="SparseCategoricalCrossentropy", optimizer="adam",metrics=["accuracy"])
model.fit(Xtrain, ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,validation_data=(Xtest, ytest))
y_pred = model.predict(Xtest)
y_pred = y_pred.argmax(axis=1)
ytest = ytest.argmax(axis=1)
print("保存模型")
model.save('my_model.h5')
print("加载模型")
model = load_model('my_model.h5')
INPUT_SENTENCES = ['一根大阳线','财务报表','数据好看','神经病公司']
XX = np.empty(len(INPUT_SENTENCES),dtype=list)
i=0
for sentence in INPUT_SENTENCES:
words = jieba.cut(sentence)
seq = []
for word in words:
if word in word2index:
seq.append(word2index[word])
else:
seq.append(word2index['UNK'])
XX[i] = seq
i+=1
XX = sequence.pad_sequences(XX, maxlen=MAX_SENTENCE_LENGTH)
label2word = {0:'喜悦', 1:'愤怒', 2:'厌恶', 3:'低落'}
for x in model.predict(XX):
print(x)
x = x.tolist()
label = x.index(max(x[0], x[1], x[2], x[3]))
print(label)
print('{}'.format(label2word[label]))
|