Home > Project > Economy&Business > System Design > Crawling & Updating
Project 1: Financial Work Flow
Designing Background
I developed an automated process to acquire and analyze financial data from annual reports and understand business operations. This process caters to the growing need for financial data processing and analysis in today’s digital and information-driven context.
It enables businesses to effectively gather and analyze financial data from the last three years. The process fetches annual report data, analyzes data, generates analytical reports, and computes financial figures.
Github:https://github.com/Viiiikedy/RPA
Financial Website:http://www.cninfo.com.cn/new/index
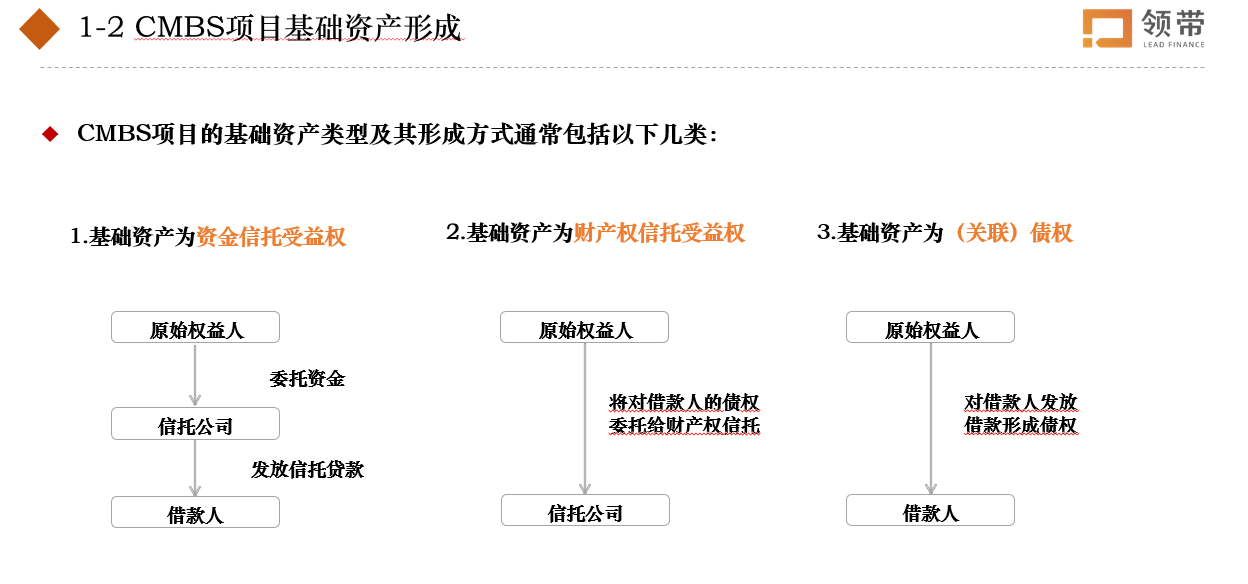
Designing Procedure
Designing Execution
Open the software, select “project.json,” and install the extension for Edge in the tools section.
Delete the already executed .docx, .pdf, and .xlsx files for Shanghai Airport, 2022, and Fujian Expressway. The specific company codes can be found in the “企业列表.xlsx” (Company List.xlsx) file, formatted as follows:
Select the “Main. xaml” file and click “run the file.” The annual report download data source is the Juchao website, and the data template is located in “word模板.docx” (word template.docx), formatted as follows:
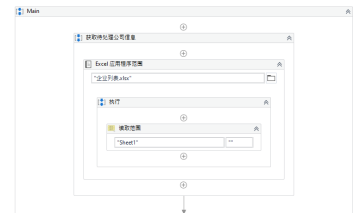
Company Code Company Name Quick Ratio [Company Code] [Company Name] [Quick Ratio] Start the process; below is a screenshot of part of the running code.
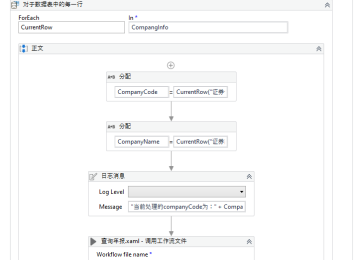
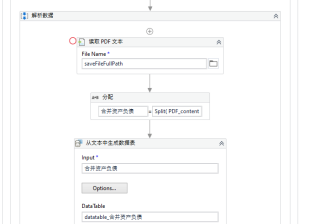
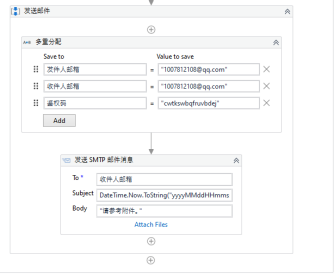
Project 2: News Automatically Crawling and Categorization
China Government News-Headline
Step 1: Package Importing
1 | for i in range(len(title)): |
Step 2:Crawling
1 | import requests |
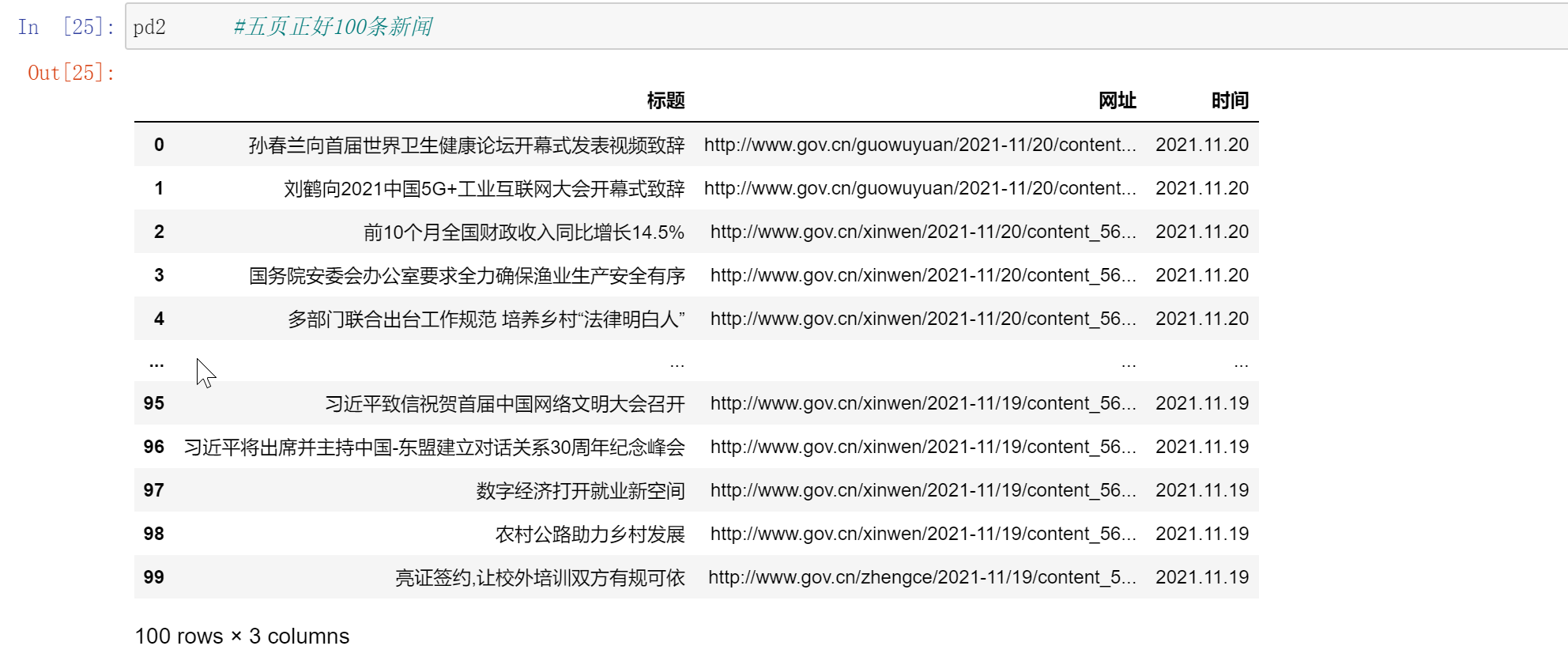
Step 3:Categorization
1. Key words
Consumer Discretionary,Consumer Staples,Energy,Materials,Finance,Industry,Healthcare,Information Technology,Telecom Services,Utilities,Real Estate——Based on the Global Industry Classification Standard (GICS)
1 | score = [] |
2. Matching
Match the news title and content with the key word.IF matched,the related industry receive 5 score.In this way,we get the final score for every news,such as[5,15,20,5,0]
1 | industry_name = ['Energy', 'Macroeconomics', 'Manufacturing', 'Education', 'Healthcare'] |

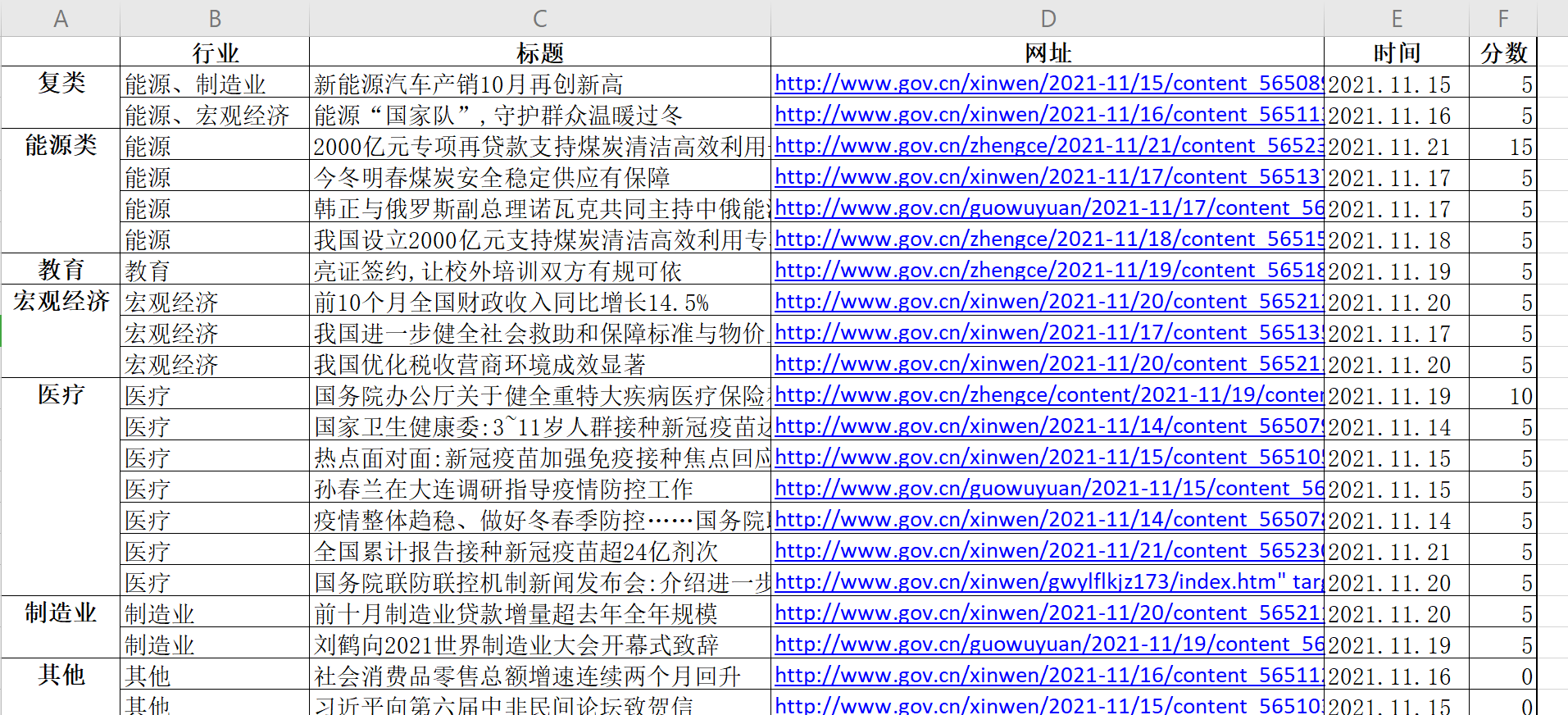
Categorized Data Sample
Project 3: Automatically Transfer PPT to Word
1. Extract only the text and images from the PPT.
Use a for loop to iterate through each shape in the PPT, first check if the shape contains a text box, and if so, extract the text within it. All information in computers is stored in binary form (1010), including images. When reading files, the character stream automatically encodes these binaries using a character encoding table, but images are already binary files and don’t need to be encoded.
Based on this principle, retrieve the binary stream of each page in the PPT, determine if it is an image based on the file extension, and if it is, extract and save it as an image, then insert it into a Word document.
1 | # 1. Import necessary libraries and functions |


2. Extract the title of the PPT.
The main difficulty here is that the titles in the PPT are not actually formatted as proper titles, but rather the body content with enlarged and bolded fonts. However, we can observe that all the titles follow a similar format like “1-1,” which is “number-number text.” Based on this, we can determine if a paragraph is a title in the PPT by checking if it matches this specific format.